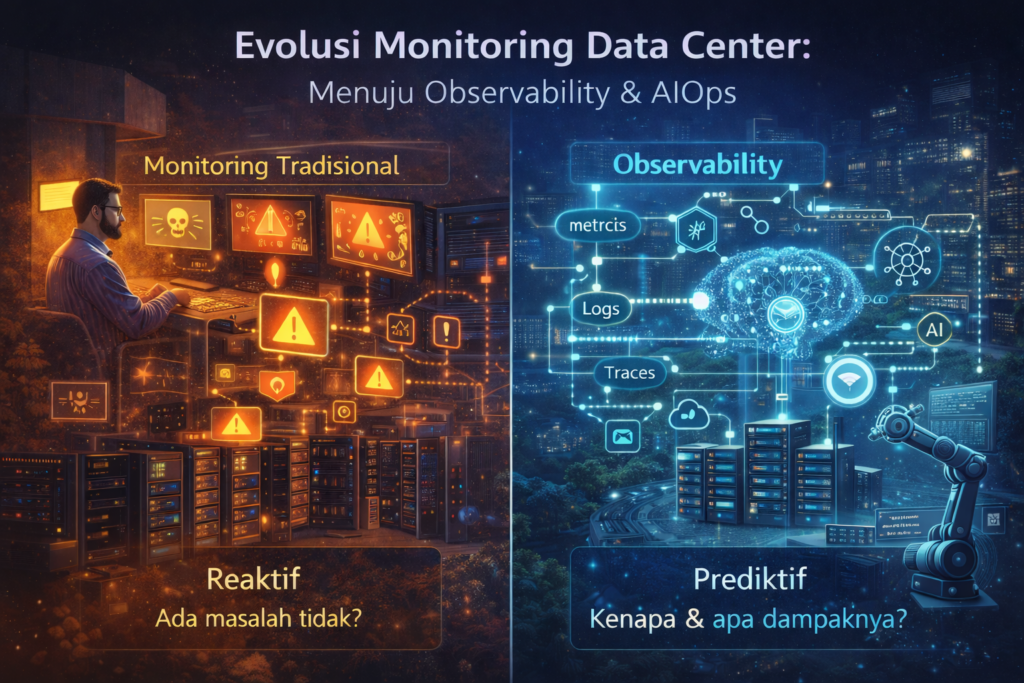
Di masa awal operasional data center, cara mengetahui ada gangguan sebenarnya sangat sederhana. Jika ada sistem mati, baru ketahuan. Jika user mengeluh email tidak bisa diakses atau aplikasi lambat, barulah tim IT bergerak.
Artinya, masalah harus terjadi dulu sebelum diperbaiki.
Pendekatan ini wajar pada masa itu. Infrastruktur masih kecil, server belum banyak, dan ketergantungan bisnis terhadap sistem digital belum sebesar sekarang. Downtime satu jam mungkin masih bisa ditoleransi.
Namun ketika data center mulai menjadi tulang punggung bisnis, pendekatan reaktif seperti ini jelas berisiko. Satu server mati bisa berdampak ke ratusan user. Satu storage bermasalah bisa menghentikan banyak aplikasi sekaligus.
Menunggu komplain bukan lagi pilihan.
Era monitoring dasar
Langkah berikutnya adalah monitoring.
Tim mulai memasang tool untuk memantau kondisi perangkat secara real-time. Server dipantau status hidup atau mati. CPU usage dicek. Kapasitas storage dipantau. Network diawasi.
Ketika melewati batas tertentu, alarm berbunyi.
Ini adalah lompatan besar. Tim tidak lagi buta terhadap kondisi sistem. Gangguan bisa diketahui lebih cepat, bahkan sebelum user menyadarinya.
Namun seiring waktu, muncul masalah baru.
Semakin besar data center, semakin banyak alert yang muncul. Puluhan, ratusan, bahkan ribuan notifikasi per hari. Sebagian penting, sebagian tidak. Tim justru kewalahan memilah mana yang benar-benar kritikal.
Monitoring tradisional hanya menjawab satu pertanyaan: “ada masalah atau tidak?”
Bukan “kenapa”, dan bukan “apa dampaknya”.
Keterbatasan pendekatan lama
Data center modern tidak lagi sederhana.
Satu aplikasi bisa bergantung pada banyak komponen sekaligus: hypervisor, VM, storage, network, database, load balancer, dan layanan lainnya. Jika salah satu melambat, semuanya ikut terasa lambat.
Monitoring biasa hanya menunjukkan gejala di permukaan. CPU tinggi, disk penuh, atau latency naik. Tetapi akar masalah sering tersembunyi di lapisan lain.
Akibatnya, tim menghabiskan banyak waktu untuk menebak-nebak. Troubleshooting menjadi lama, downtime bertambah, dan tekanan operasional meningkat.
Semakin kompleks sistemnya, semakin sulit memahami apa yang sebenarnya terjadi.
Munculnya observability
Dari kebutuhan inilah lahir konsep observability.
Observability bukan sekadar memantau status, tetapi memahami perilaku sistem secara menyeluruh.
Pendekatan ini menggabungkan tiga komponen utama: metrics, logs, dan traces. Semua data operasional dikumpulkan, dikorelasikan, lalu divisualisasikan sebagai satu kesatuan.
Dengan observability, tim tidak hanya tahu bahwa aplikasi lambat, tetapi bisa menelusuri sampai ke service mana yang bottleneck, host mana yang bermasalah, atau proses mana yang memicu error.
Fokusnya bukan hanya “apa yang salah”, tetapi “mengapa itu terjadi”.
Secara profesional, ini mengubah troubleshooting dari sekadar reaksi menjadi analisis berbasis data.
Peran AIOps dalam skala besar
Namun ketika data semakin besar, manusia tidak lagi mampu membaca semuanya secara manual.
Di sinilah AIOps (Artificial Intelligence for IT Operations) berperan.
AIOps menggunakan analitik dan machine learning untuk membantu operasional, seperti:
- mengurangi noise alert
- mendeteksi anomali secara otomatis
- mengkorelasikan banyak event menjadi satu insiden
- memprediksi potensi kegagalan
- bahkan melakukan perbaikan otomatis
Alih-alih menunggu storage benar-benar penuh, sistem bisa memberi peringatan beberapa hari sebelumnya. Alih-alih menunggu server crash, sistem bisa mendeteksi pola aneh dan memberi sinyal dini.
Pendekatan ini mengubah operasional dari reaktif menjadi prediktif.
Bukan lagi “memperbaiki setelah rusak”, tetapi “mencegah sebelum rusak”.
Inilah fondasi dari modern data center operations.
Dampak pada keandalan layanan
Dengan observability dan AIOps, tim bisa menemukan akar masalah lebih cepat, mengurangi MTTR, dan menekan downtime. Sistem menjadi lebih stabil, layanan lebih andal, dan operasional lebih efisien.
Data center tidak lagi sekadar bertahan dari gangguan, tetapi mampu mengantisipasinya.
Bagi bisnis, ini berarti satu hal penting: kepercayaan.
Karena layanan yang jarang bermasalah jauh lebih bernilai daripada layanan yang sering diperbaiki.
Penutup
Untuk membayangkannya secara sederhana, bayangkan Anda mengelola mobil.
Cara lama seperti menunggu mobil mogok di jalan baru membawanya ke bengkel. Monitoring seperti lampu indikator menyala ketika ada masalah. Observability seperti dashboard lengkap yang menunjukkan kondisi mesin secara detail. AIOps seperti mobil pintar yang sudah memperingatkan bahwa komponen tertentu akan rusak minggu depan, bahkan menyarankan jadwal servis.
Begitulah evolusi operasional data center.
Dari sekadar mengetahui kerusakan, menjadi memahami sistem, hingga akhirnya mampu memprediksi masa depan.

